| YOLO算法的原理与实现 | 您所在的位置:网站首页 › yolo s › YOLO算法的原理与实现 |
YOLO算法的原理与实现
1、前言
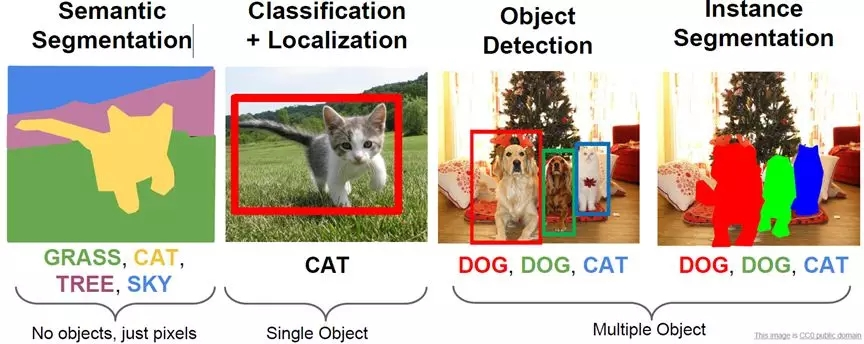
当我们谈起计算机视觉时,首先想到的就是图像分类,没错,图像分类是计算机视觉最基本的任务之一,但是在图像分类的基础上,还有更复杂和有意思的任务,如目标检测,物体定位,图像分割等,见图1所示。其中目标检测是一件比较实际的且具有挑战性的计算机视觉任务,其可以看成图像分类与定位的结合,给定一张图片,目标检测系统要能够识别出图片的目标并给出其位置,由于图片中目标数是不定的,且要给出目标的较精确位置,目标检测相比分类任务更复杂。目标检测的一个实际应用场景就是无人驾驶,如果能够在无人车上装载一个有效的目标检测系统,那么无人车将和人一样有了眼睛,可以快速地检测出前面的行人与车辆,从而作出实时决策。
在介绍Yolo算法之前,首先先介绍一下滑动窗口技术,这对我们理解Yolo算法是有帮助的。采用滑动窗口的目标检测算法思路非常简单,它将检测问题转化为了图像分类问题。其基本原理就是采用不同大小和窗口在整张图片上以一定的步长进行滑动,然后对这些窗口对应的区域做图像分类,这样就可以实现对整张图片的检测了,如下图3所示,如DPM就是采用这种思路。但是这个方法有致命的缺点,就是你并不知道要检测的目标大小是什么规模,所以你要设置不同大小的窗口去滑动,而且还要选取合适的步长。但是这样会产生很多的子区域,并且都要经过分类器去做预测,这需要很大的计算量,所以你的分类器不能太复杂,因为要保证速度。解决思路之一就是减少要分类的子区域,这就是R-CNN的一个改进策略,其采用了selective search方法来找到最有可能包含目标的子区域(Region Proposal),其实可以看成采用启发式方法过滤掉很多子区域,这会提升效率。 2、滑动窗口与CNN 在介绍Yolo算法之前,首先先介绍一下滑动窗口技术,这对我们理解Yolo算法是有帮助的。采用滑动窗口的目标检测算法思路非常简单,它将检测问题转化为了图像分类问题。其基本原理就是采用不同大小和窗口在整张图片上以一定的步长进行滑动,然后对这些窗口对应的区域做图像分类,这样就可以实现对整张图片的检测了,如下图3所示,如DPM就是采用这种思路。但是这个方法有致命的缺点,就是你并不知道要检测的目标大小是什么规模,所以你要设置不同大小的窗口去滑动,而且还要选取合适的步长。但是这样会产生很多的子区域,并且都要经过分类器去做预测,这需要很大的计算量,所以你的分类器不能太复杂,因为要保证速度。解决思路之一就是减少要分类的子区域,这就是R-CNN的一个改进策略,其采用了selective search方法来找到最有可能包含目标的子区域(Region Proposal),其实可以看成采用启发式方法过滤掉很多子区域,这会提升效率。 
如果你使用的是CNN分类器,那么滑动窗口是非常耗时的。但是结合卷积运算的特点,我们可以使用CNN实现更高效的滑动窗口方法。这里要介绍的是一种全卷积的方法,简单来说就是网络中用卷积层代替了全连接层,如图4所示。输入图片大小是16x16,经过一系列卷积操作,提取了2x2的特征图,但是这个2x2的图上每个元素都是和原图是一一对应的,如图上蓝色的格子对应蓝色的区域,这不就是相当于在原图上做大小为14x14的窗口滑动,且步长为2,共产生4个字区域。最终输出的通道数为4,可以看成4个类别的预测概率值,这样一次CNN计算就可以实现窗口滑动的所有子区域的分类预测。这其实是overfeat算法的思路。之所可以CNN可以实现这样的效果是因为卷积操作的特性,就是图片的空间位置信息的不变性,尽管卷积过程中图片大小减少,但是位置对应关系还是保存的。说点题外话,这个思路也被R-CNN借鉴,从而诞生了Fast R-CNN算法。  上面尽管可以减少滑动窗口的计算量,但是只是针对一个固定大小与步长的窗口,这是远远不够的。Yolo算法很好的解决了这个问题,它不再是窗口滑动了,而是直接将原始图片分割成互不重合的小方块,然后通过卷积最后生产这样大小的特征图,基于上面的分析,可以认为特征图的每个元素也是对应原始图片的一个小方块,然后用每个元素来可以预测那些中心点在该小方格内的目标,这就是Yolo算法的朴素思想。下面将详细介绍Yolo算法的设计理念。
这就是Yolo算法的朴素思想。下面将详细介绍Yolo算法的设计理念
3、设计理念
整体来看,Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,整个系统如图5所示:首先将输入图片resize到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。相比R-CNN算法,其是一个统一的框架,其速度更快,而且Yolo的训练过程也是end-to-end的。
上面尽管可以减少滑动窗口的计算量,但是只是针对一个固定大小与步长的窗口,这是远远不够的。Yolo算法很好的解决了这个问题,它不再是窗口滑动了,而是直接将原始图片分割成互不重合的小方块,然后通过卷积最后生产这样大小的特征图,基于上面的分析,可以认为特征图的每个元素也是对应原始图片的一个小方块,然后用每个元素来可以预测那些中心点在该小方格内的目标,这就是Yolo算法的朴素思想。下面将详细介绍Yolo算法的设计理念。
这就是Yolo算法的朴素思想。下面将详细介绍Yolo算法的设计理念
3、设计理念
整体来看,Yolo算法采用一个单独的CNN模型实现end-to-end的目标检测,整个系统如图5所示:首先将输入图片resize到448x448,然后送入CNN网络,最后处理网络预测结果得到检测的目标。相比R-CNN算法,其是一个统一的框架,其速度更快,而且Yolo的训练过程也是end-to-end的。
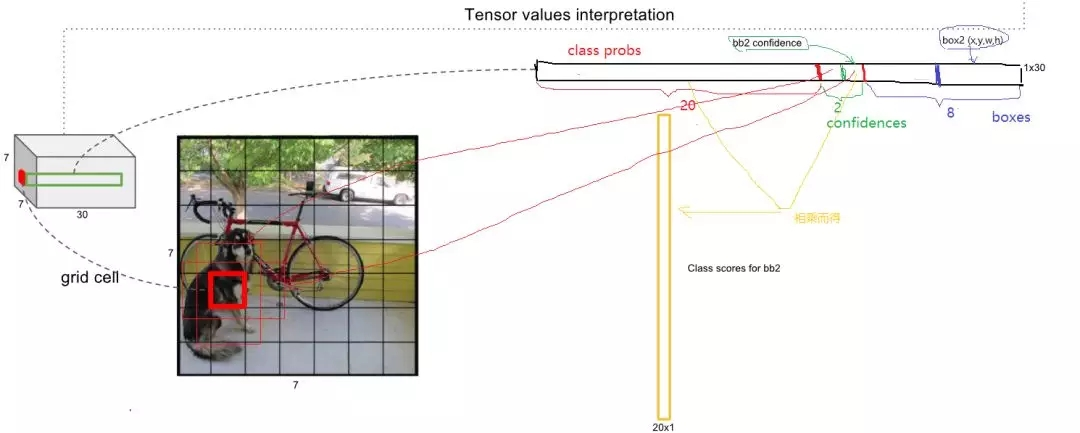
总结一下,每个单元格需要预测(B*5+C)个值。如果将输入图片划分为S*S网格,那么最终预测值为S*S*(B*5+C)大小的张量。整个模型的预测值结构如下图所示。对于PASCALVOC数据,其共有20个类别,如果使用S=7,B=2,那么最终的预测结果就是7*7*30大小的张量。在下面的网络结构中我们会详细讲述每个单元格的预测值的分布位置。
4、网络设计 Yolo采用卷积网络来提取特征,然后使用全连接层来得到预测值。网络结构参考GooLeNet模型,包含24个卷积层和2个全连接层,如图8所示。对于卷积层,主要使用1x1卷积来做channle reduction,然后紧跟3x3卷积。对于卷积层和全连接层,采用Leaky ReLU激活函数:max(x,0)。但是最后一层却采用线性激活函数。除了上面这个结构,文章还提出了一个轻量级版本Fast Yolo,其仅使用9个卷积层,并且卷积层中使用更少的卷积核。 

5、网络训练 在训练之前,先在ImageNet上进行了预训练,其预训练的分类模型采用图8中前20个卷积层,然后添加一个average-pool层和全连接层。预训练之后,在预训练得到的20层卷积层之上加上随机初始化的4个卷积层和2个全连接层。由于检测任务一般需要更高清的图片,所以将网络的输入从224x224增加到了448x448。整个网络的流程如下图所示: 
另外一点时,由于每个单元格预测多个边界框。但是其对应类别只有一个。那么在训练时,如果该单元格内确实存在目标,那么只选择与ground truth的IOU较大的那个边界框来负责预测该目标,而其它边界框认为不存在目标。这样设置的一个结果将会使一个单元格对应的边界框更加专业化,其可以分别适用不同大小,不同高宽比的目标,从而提升模型性能。大家可能会想如果一个单元格内存在多个目标怎么办,其实这时候Yolo算法就只能选择其中一个来训练,这也是Yolo算法的缺点之一。要注意的一点时,对于不存在对应目标的边界框,其误差项就是只有置信度,左标项误差是没法计算的。而只有当一个单元格内确实存在目标时,才计算分类误差项,否则该项也是无法计算的。 综上讨论,最终的损失函数计算如下:
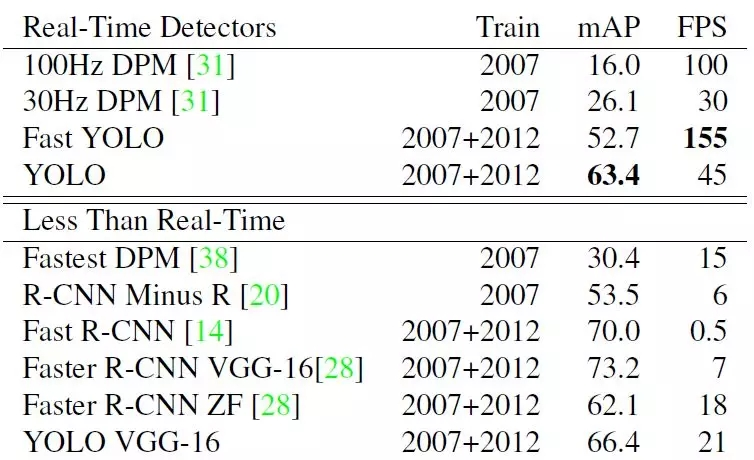
Yolo在PASCAL VOC 2007上与其他算法的对比
|

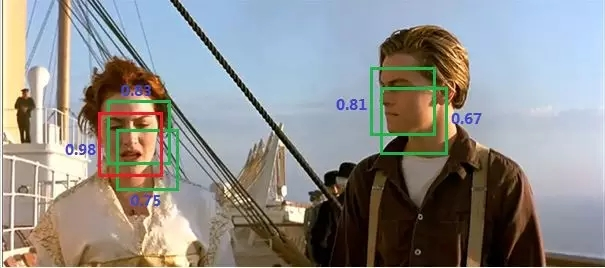
 具体来说,Yolo的CNN网络将输入的图片分割成S*S网格,然后每个单元格负责去检测那些中心点落在该格子内的目标,如图6所示,可以看到狗这个目标的中心落在左下角一个单元格内,那么该单元格负责预测这个狗。每个单元格会预测B个边界框(bounding box)以及边界框的置信度(confidence score)。所谓置信度其实包含两个方面,一是这个边界框含有目标的可能性大小,二是这个边界框的准确度。前者记为Pr(object),当该边界框是背景时(即不包含目标),此时Pr(object)=0。而当该边界框包含目标时,Pr(object)=1。边界框的准确度可以用预测框与实际框(ground truth)的IOU(intersection over union,交并比)来表征,记为IOU。因此置信度可以定义为Pr(object)*IOU。很多人可能将Yolo的置信度看成边界框是否含有目标的概率,但是其实它是两个因子的乘积,预测框的准确度也反映在里面。边界框的大小与位置可以用4个值来表征:(x,y,h,w),其中(x,y)是边界框的中心坐标,而和是边界框的宽与高。还有一点要注意,中心坐标的预测值(x,y)是相对于每个单元格左上角坐标点的偏移值,并且单位是相对于单元格大小的,单元格的坐标定义如图6所示。而边界框的w和h预测值是相对于整个图片的宽与高的比例,这样理论上4个元素的大小应该在[0,1]范围。这样,每个边界框的预测值实际上包含5个元素:(x,y,w,h,c),其中前4个表征边界框的大小与位置,而最后一个值是置信度。
具体来说,Yolo的CNN网络将输入的图片分割成S*S网格,然后每个单元格负责去检测那些中心点落在该格子内的目标,如图6所示,可以看到狗这个目标的中心落在左下角一个单元格内,那么该单元格负责预测这个狗。每个单元格会预测B个边界框(bounding box)以及边界框的置信度(confidence score)。所谓置信度其实包含两个方面,一是这个边界框含有目标的可能性大小,二是这个边界框的准确度。前者记为Pr(object),当该边界框是背景时(即不包含目标),此时Pr(object)=0。而当该边界框包含目标时,Pr(object)=1。边界框的准确度可以用预测框与实际框(ground truth)的IOU(intersection over union,交并比)来表征,记为IOU。因此置信度可以定义为Pr(object)*IOU。很多人可能将Yolo的置信度看成边界框是否含有目标的概率,但是其实它是两个因子的乘积,预测框的准确度也反映在里面。边界框的大小与位置可以用4个值来表征:(x,y,h,w),其中(x,y)是边界框的中心坐标,而和是边界框的宽与高。还有一点要注意,中心坐标的预测值(x,y)是相对于每个单元格左上角坐标点的偏移值,并且单位是相对于单元格大小的,单元格的坐标定义如图6所示。而边界框的w和h预测值是相对于整个图片的宽与高的比例,这样理论上4个元素的大小应该在[0,1]范围。这样,每个边界框的预测值实际上包含5个元素:(x,y,w,h,c),其中前4个表征边界框的大小与位置,而最后一个值是置信度。





【本文地址】